Introduction
Clustered and longitudinal analysis
Individual level RCT: randomize individuals to control group and treatment group and measure the outcome for both groups. Vast majority of data analysis of RCTs and observational data uses some from of regression (linear, logistic, generalized linear models, …)
Simplest case is linear regression with single covariate, and using ordinary least squares (OLS) regression method:
\[
Y_i = \beta_{0} + \beta_{1}X_i+e_i
\]
where \(e_i\) is random error with variance \(\sigma^2\). This method assumes that errors \(e_i\) are independent of (uncorrelated with) each other:
\[
Cov(e_i,e_j) = 0 \ when \ i \neq j
\]
However, clustered and longitudinal data often be expected to be correlation with group (cluster):
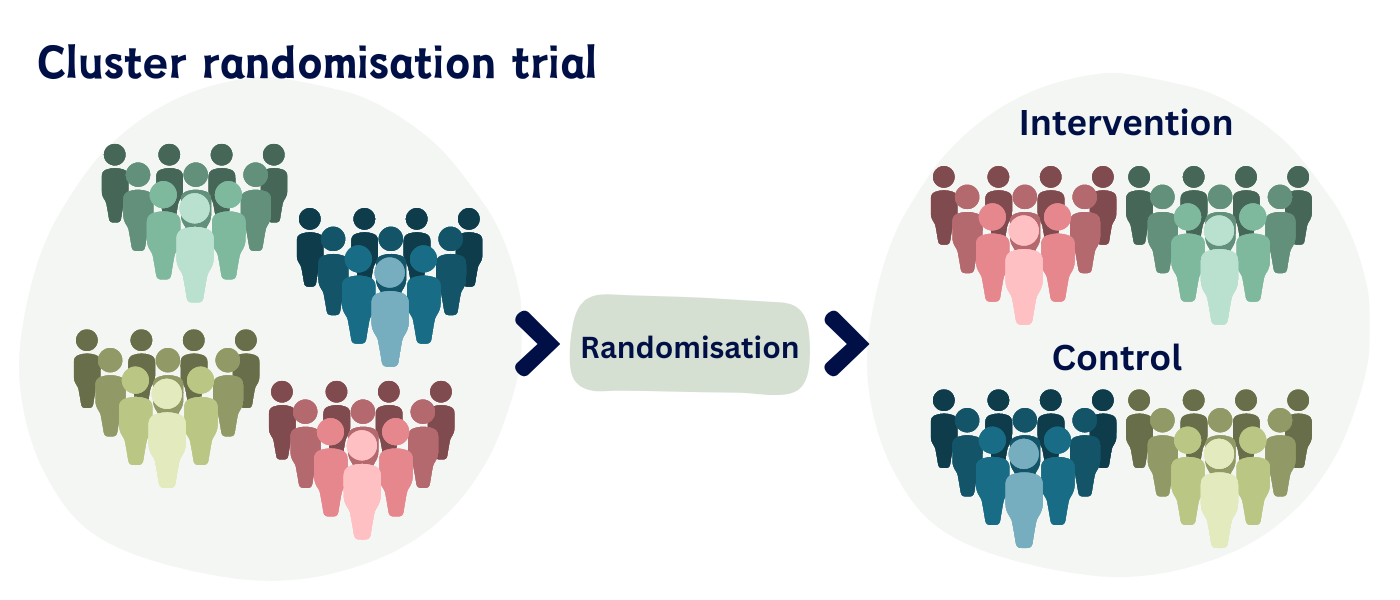
individuals may belong to clusters such as families, schools, medical centers. (clustered)
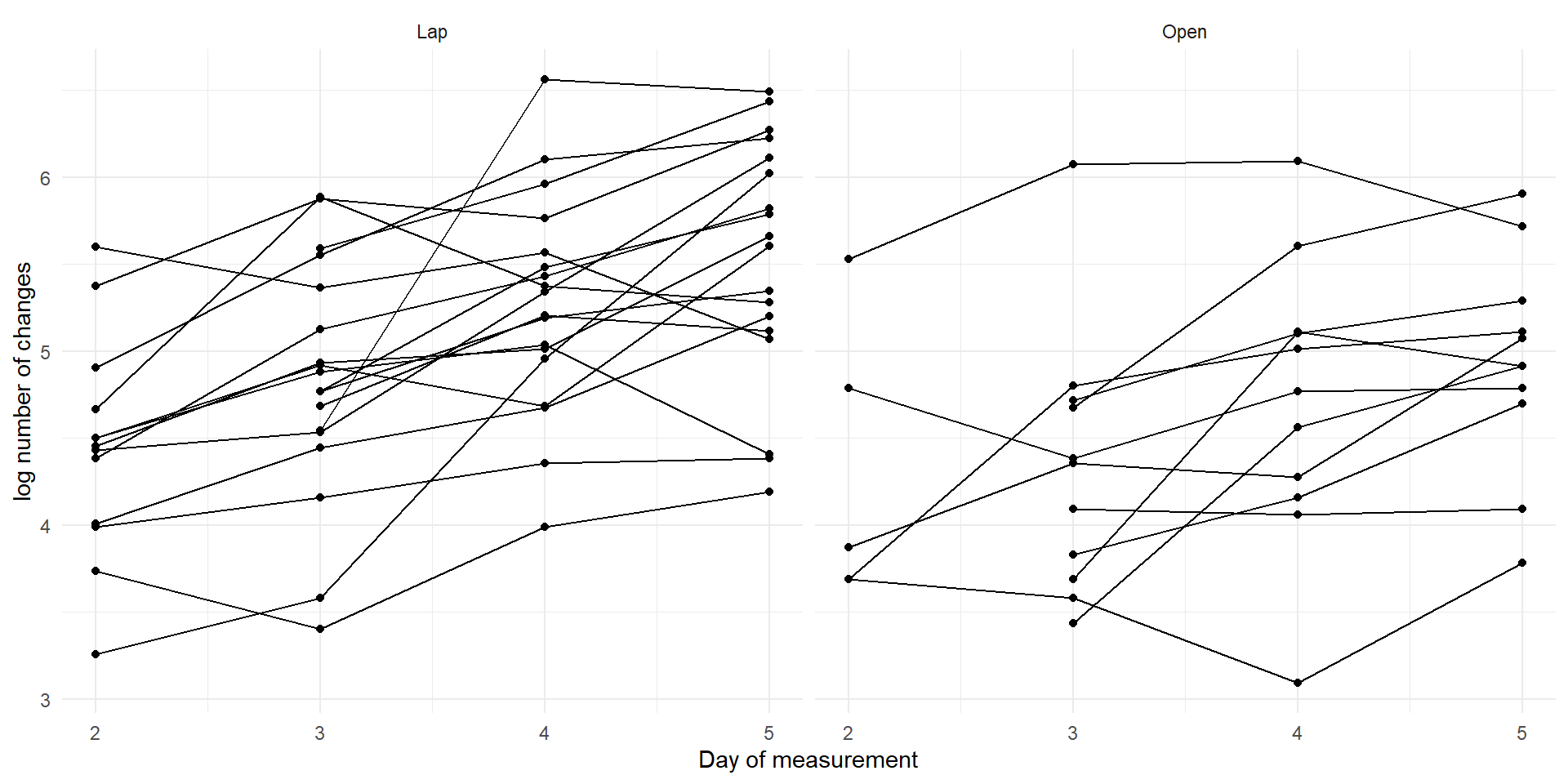
the ‘units’ are not individuals but are repeated measures of the same variable on an individual over time. (longitudinal)
=> It is not make sense to assume the errors in the regression model are all uncorrelated with each other
=> If using OLS regression methods (ignoring the correlation structure) to those type of data will generally product unbiased estimates of effect but:
How to choose method of analysis
Based on:
Data structure
Research question
Comparing within cluster
When analysis question involves comparisons within clusters, considering the clustering increases precision of estimation (lower standard errors, smaller P-values). Because we are removing a source of variation from the comparison
Data structure examples:
Comparing between clusters
When analysis question involves comparisons between clusters, considering the clustering decreases precision of estimation (higher standard errors, higher P-values). Because positive intra-cluster correlation reduces the amount of independent information provided by individuals
Data structure examples:
Summary
Study designs have the correlated observations:
Clusters – individuals from the same family, hospital, school
Longitudinal data – repeated measures of an outcome on the same individual
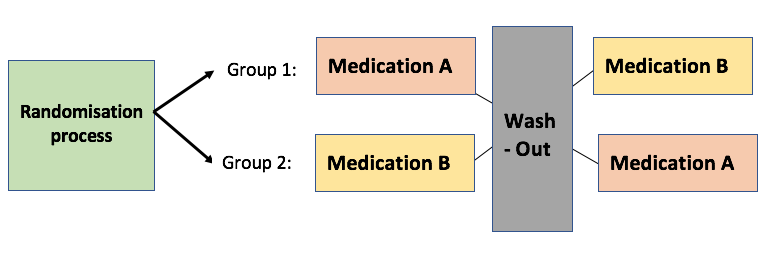
Paired data – two measurements from the same individual (e.g. cross-over trials)
=> If we ignore this correlation, conclusions obtained will be misleading: Incorrect standard errors (will be illustrated in the next section Comparison within cluster)
Accounting for clustering: