Classification
Introduction to classification
The aim of classification is to group (partition, segment) \(n\) observations into a number of homogeneous groups or classes. There are two main types of classification :
Supervised classification, often referred to simply as classification
Unsupervised classification, sometimes called partitioning, segmentation, or clustering.
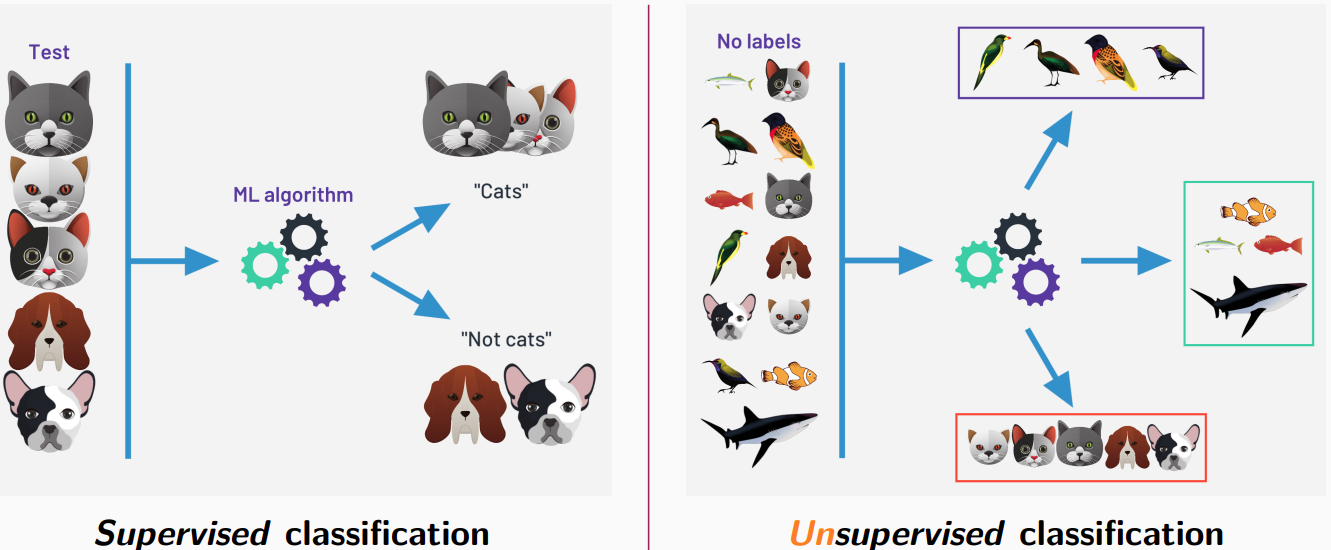
Supervised classification
In supervised classification,
We already know how many groups exist in the population
We know the group to which each observation in the population belongs
We want to classify the observations in the right groups based on different variables
We can then use a classification rule to predict the groups to which new observations belong.
Some examples of applications:
Recognize hand written numbers
Identify the type of cancer patients has
There are several families of supervised classification methods. The most common are nearest neighbor method, discriminant factor analysis, classification trees, logistic regression, naive Bayesian, neural networks, support vector machines.
We have the data with n individuals described by their values of X and Y.
\[\begin{aligned} X_n = \begin{bmatrix} x_{11} & x_{12} & x_{13} & \dots & x_{1p} \\ x_{21} & x_{22} & x_{23} & \dots & x_{2p} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ x_{n1} & x_{n2} & x_{n3} & \dots & x_{np} \end{bmatrix} \quad , \quad Y_n = \begin{bmatrix} y_{1} \\ y_{2} \\ \vdots \\ y_{n} \end{bmatrix} \end{aligned}\]We want to predict the class \(y_0\) of a new input \(x_0 = (x_{01},x_{02},...,x_{0p})\)
Unsupervised classification
In unsupervised classification,
In general, we don’t know how many groups exist in the population
We don’t know the group to which each observation in the population belongs
We want to classify observations into homogeneous groups based on different variables
Application examples:
In psychology : the determination of personality types present in a group of individuals
In text mining : partitioning e-mails or texts according to subject
There are several families of unsupervised classification methods. The most common are hierarchical classification, k-means method, density-based classification, mixture of normal distributions.