logical(0)logical(0)Optimal partition:
Choose from all the partitions into K classes the one with the greatest inter inertia.
Problem : number of partitions into K classes of the n individuals \(\sim \frac{K^n}{K!}.K!\)
=> Complete enumeration impossible.
Locally optimal partition - Heuristic of the type :
We start from a feasible solution, i.e. a partition \(\mathscr{P}_K^0\)
At step t + 1, we look for a partition \(\mathscr{P}_{K}^{t+1} = g(\mathscr{P}_{K}^{t})\) such that inertia_inter(\(\mathscr{P}_{K}^{t+1}\)) inertia_inter(\(\mathscr{P}_{K}^{t}\))
Stop when no individual changes class between two iterations
=> Method for partitioning K-means.
Initialization step:
Choosing the number of classes K
Random drawing of K class centers (K individuals among n)
Iteration(Repeat until convergence):
Assignment step: each individual is assigned to the class whose center of gravity is the closest.
Representation step: the centers of gravity of the classes are calculated.
logical(0)logical(0)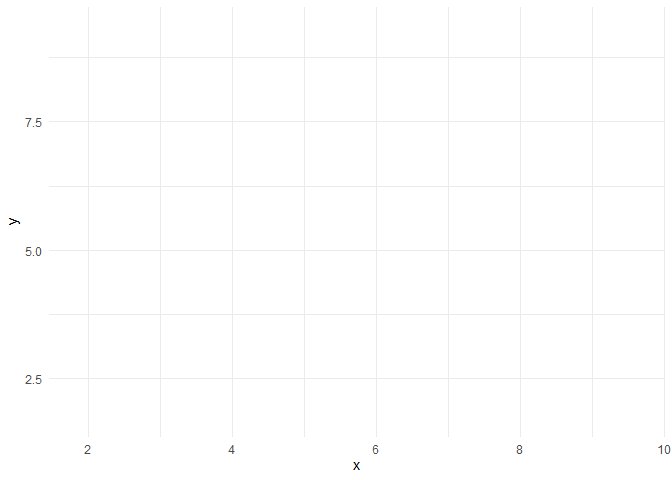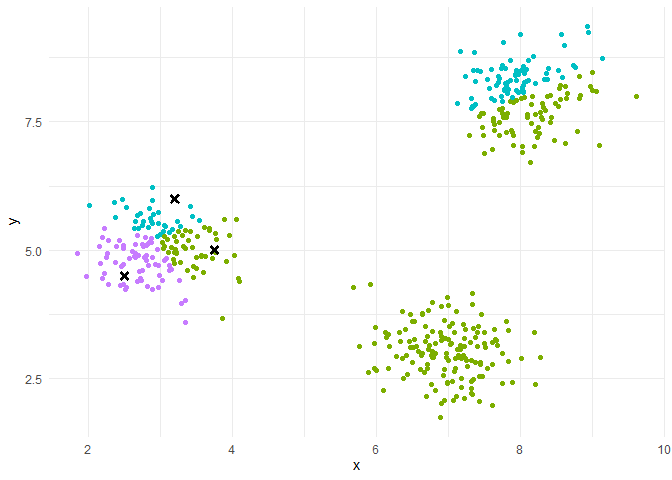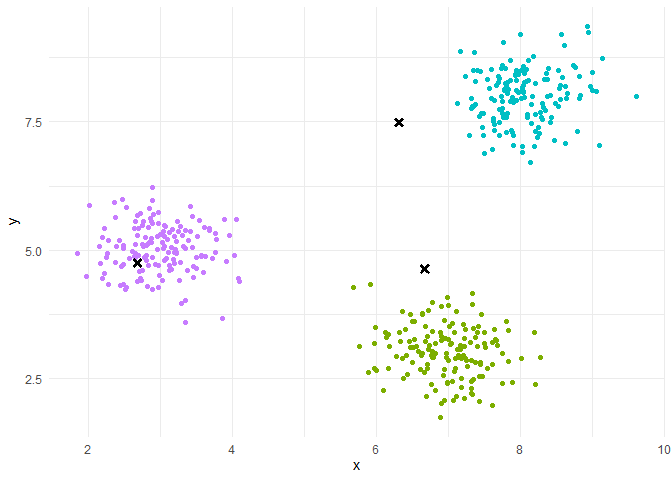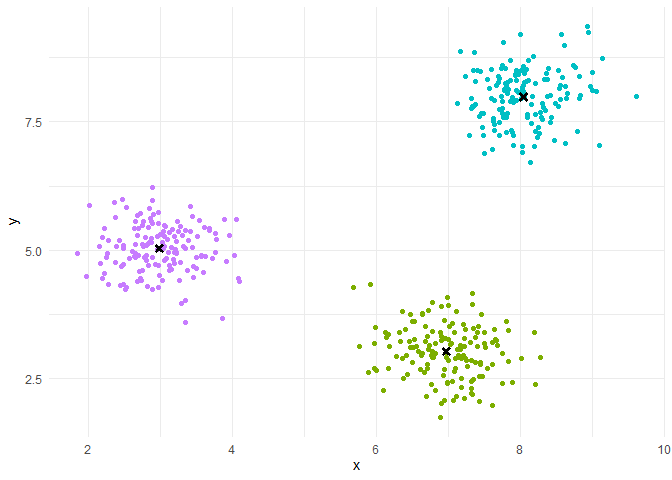
Random assignment: K random points in the scatterplot
k-means++ assignment: Choose 1 centroid randomly. 2nd centroid at a large distance from the 1st with large prob. : sample a point according to 1 prob, law propor, to the distance to the 1st centroid.


The final partition depends on the initial partition : if we restart the algorithm with other initial centers, the final partition can be different.
In practice:
We run the algorithm N times with different random initializations.
We retain among the N final partitions, the one with the largest percentage of explained inertia.
Advantages:
Relatively efficient (fast).
Linear complexity in the number of individuals.
Tends to reduce intra-class inertia at each iteration.
Tends to increase inter-class inertia at each iteration.
Forms compact and well-separated classes.Relatively efficient (fast).
Disadvantages:
Choice of the number of classes.
Influence of the choice of initial centroids.
Convergence towards a local minimum of intra-class inertia.
Convergence towards a local maximum of the inter-class inertia.
Requires the notion of center of gravity.
Influence of outliers (due to the mean).
library(cluster)
library(factoextra)
library(ggplot2)
library(plotly)
library(gridExtra)set.seed(123)
n <- 150
data <- data.frame(
x = c(rnorm(n, mean = 2, sd = 0.5), rnorm(n, mean = 6, sd = 0.5), rnorm(n, mean = 10, sd = 0.5)),
y = c(rnorm(n, mean = 10, sd = 0.5), rnorm(n, mean = 6, sd = 0.5), rnorm(n, mean = 2, sd = 0.5))
)ggplot(data, aes(x, y)) +
geom_point() +
theme_minimal()
set.seed(123)
kmeans_result_1 <- kmeans(data, centers = 3)
data$kmeans_result_1 <- as.factor(kmeans_result_1$cluster)
# Visualization of the results
ggplot(data, aes(x = x, y = y, color = kmeans_result_1)) +
geom_point(size = 3) +
ylim(0,12) +
labs(title = "Results of k-means with outliers", color = "Cluster") +
theme_minimal()
The k-means method relies on distance calculations (usually the Euclidean distance) to group points into clusters. If the variables have different scales, those with larger amplitudes will have a disproportionate influence on the calculation of distances, which can distort the clustering results.
Example:
If one variable is measured in kilometers and another in meters, the first will dominate the calculations.
Renormalizing (often using standardization or normalization) allows to put all variables on the same scale, preventing some variables from biasing the distances.
Add the 3rd variables with a different scale
data$z <- c(rnorm(2 * n, mean = 50, sd = 5), rnorm(n, mean = 100, sd = 5))
head(data) x y kmeans_result_1 z
1 1.719762 10.715201 3 57.79354
2 1.884911 10.523314 3 50.35254
3 2.779354 10.217644 3 50.64644
4 2.035254 10.357589 3 58.57532
5 2.064644 10.458587 3 52.30458
6 2.857532 8.669539 3 43.67469data_scaled <- scale(data[,c(1,2,4)])Data without renormalization
Data with renormalization
# Comparison with and without renormalisation
# k-means without renormalization
kmeans_no_scaling <- kmeans(data, centers = 3, nstart = 25)
data$cluster_no_scaling <- as.factor(kmeans_no_scaling$cluster)
# k-means with renormalization
data_scaled <- scale(data[,c(1,2,4)])
kmeans_scaling <- kmeans(data_scaled, centers = 3, nstart = 25)
data$cluster_scaling <- as.factor(kmeans_scaling$cluster)
# Data visualization
p1 <- ggplot(data, aes(x, y, color = cluster_no_scaling)) +
geom_point() +
ggtitle("Clustering without renormalization") +
theme_minimal()+
theme(legend.position = "none")
p2 <- ggplot(data, aes(x, y, color = cluster_scaling)) +
geom_point() +
ggtitle("Clustering with renormalisation") +
theme_minimal()+
theme(legend.position = "none")
grid.arrange(p1, p2, ncol = 2)
The elbow method aims to determine the optimal number of clusters (\(k\)) by visualizing the relationship between the number of clusters and the total intra-cluster inertia (tot.withinss).
Observation: We generally observe a rapid decrease in inertia when k increases, followed by a slowdown.
Elbow Point: The “elbow” of the graph corresponds to the point where adding an additional cluster no longer significantly improves the reduction of inertia. This point indicates the optimal number of clusters. In the given example, the elbow is observed at k=3, which suggests that 3 clusters are appropriate for the data… this is a bit of the expected result…
# Calculating intra-cluster inertia for different numbers of clusters
set.seed(123)
inertias <- sapply(1:10, function(k) {
kmeans(scale(data[,c(1,2)]), centers = k, nstart = 25)$tot.withinss
})
# Visualization of the elbow criterion
plot(1:10, inertias, type = "b", pch = 19, frame = FALSE,
xlab = "Number k of clusters", ylab = "Intra-cluster inertia",
main = "The elbow method to choose the number k of clusters")
abline(v = 3, lty = 2, col = "red")
# Silhouette computation
set.seed(123)
final_kmeans <- kmeans(scale(data[,c(1,2)]), centers = 3, nstart = 25)
silhouette_scores <- silhouette(final_kmeans$cluster, dist(scale(data[,c(1,2)])))
# Silouhette visualization
fviz_silhouette(silhouette_scores) +
ggtitle("Silouhette analyse")Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
ℹ Please use tidy evaluation idioms with `aes()`.
ℹ See also `vignette("ggplot2-in-packages")` for more information.
ℹ The deprecated feature was likely used in the factoextra package.
Please report the issue at <https://github.com/kassambara/factoextra/issues>. cluster size ave.sil.width
1 1 150 0.84
2 2 150 0.83
3 3 150 0.85